Was this page helpful?
Deploying Scylla Monitoring Stack Without Docker¶
Introduction¶
The following instructions will help to deploy Scylla Monitoring Stack in cases where you can not use the recommended Docker version.
Please note, Scylla recommends you use the Docker version as it will provide you with most updated, current Scylla Monitoring system.
Scylla Monitoring uses the following components:
Alertmanager
Grafana Loki
Prometheus
Grafana
The common scenario for users who use their own standalone installation, is that they already have such a server and would like to consolidate. We assume that that you already have Prometheus and Grafana running but we will add minimal installation instruction for all components.
We suggest that you follow the installation instruction of each of those products from their official documentation. It is also recommended that all servers will run as a service.
Minimal Production System Recommendations¶
CPU - For clusters with up to 100 cores use 2vCPUS, for larger clusters 4vCPUs
Memory - 15GB+ DRAM and proportional to the number of cores.
Disk - persistent disk storage is proportional to the number of cores and Prometheus retention period (see the following section)
Network - 1GbE/10GbE preferred
Calculating Prometheus Minimal Disk Space requirement¶
Prometheus storage disk performance requirements: persistent block volume, for example an EC2 EBS volume
Prometheus storage disk volume requirement: proportional to the number of metrics it holds and the default retention time. The default retention period is 15 days, and the disk requirement is around 6k per series per day, assuming the default scraping interval of 20s.
For example, 100k series, with a retention time of 45 days, will need
100k * 6k * 45 ~ 26GB
To account for unexpected events, like replacing or adding nodes, we recommend allocating at least x2-3 the space, in this case, ~70GB. Prometheus Storage disk does not have to be as fast as Scylla disk, and EC2 EBS, for example, is fast enough and provides HA out of the box.
Calculating Prometheus Minimal Memory Space requirement¶
Prometheus uses more memory when querying over a longer duration (e.g. looking at a dashboard on a week view would take more memory than on an hourly duration).
For Prometheus alone, you should have 60MB of memory per core in the cluster and it would use about 600MB of virtual memory per core. Because Prometheus is so memory demanding, it is a good idea to add swap, so queries with a longer duration would not crash the server.
| # ScyllaDB Nodes | # Cores Per ScyllaDB Node | # Tables Used | Prometheus Retention in Days | # Series | Prometheus RAM | Prometheus Storage |
|---|---|---|---|---|---|---|
| 0 | 0 | 0 |
The main item to set an alert on is the available disk space in the monitoring system. Data is indefinitely accrued on the Prometheus data directory. The current monitoring solution does not churn data.
Note
Confirm before installing, that your Grafana and Prometheus versions are supported by the Scylla Monitoring Stack version you want to install. Scylla-Monitoring follows the latest Prometheus and Grafana releases tightly. See the Scylla Monitoring Stack Compatibility Matrix.
Install Scylla Monitoring Stack¶
The following procedure uses a CentOS 7 based instance
Download the latest Scylla Monitoring Stack release.
wget -O scylla-monitoring.tar.gz https://github.com/scylladb/scylla-monitoring/archive/refs/tags/4.15.1.tar.gz
Open the tar
tar -xvf scylla-monitoring.tar.gz
Install Alertmanager¶
Tested with alertmanager 0.26.0 version
Install alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.26.0/alertmanager-0.26.0.linux-amd64.tar.gz
tar -xvf alertmanager-*.linux-amd64.tar.gz
Copy the following file:
rule_config.ymlfromprometheus/directory toalertmanager.ymlin the alertmanager installation directory.
For example:
cp -p /home/centos/scylla-monitoring-4.15.1/prometheus/rule_config.yml alertmanager-0.26.0.linux-amd64/alertmanager.yml
Start the Alertmanager
For example:
cd alertmanager-0.26.0.linux-amd64/
./alertmanager
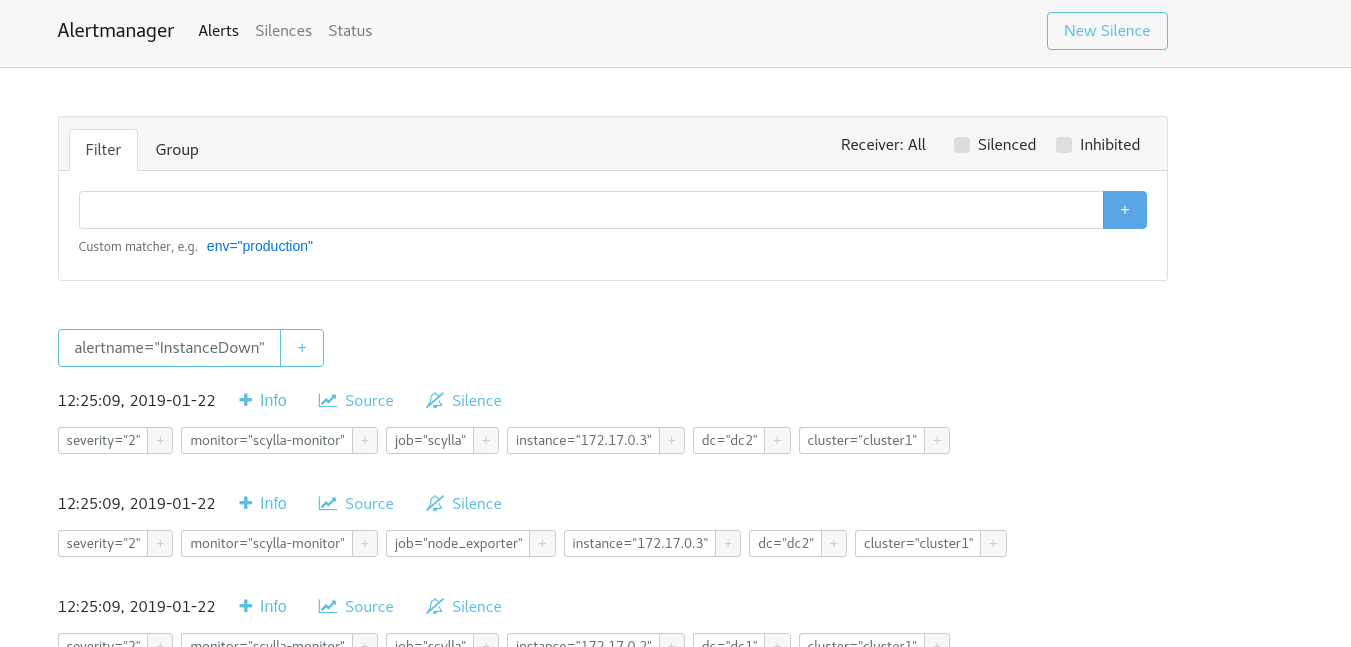
Verify that Alertmanager is up and running, point your browser to the Alertmanager IP:Port
For example:
http://192.168.135.166:9093/
Install Grafana Loki¶
Loki is a log aggregation system inspired by Prometheus. Scylla Monitoring uses Loki for alerts and metrics generation. It does not replaces your centralized logging server, but it can, check Loki-Grafana documentation if you want to use it for centralized log collection.
We recomand using Loki with containers, but you can install it locally as described in Loki installation
You will need to run both Loki and Promtail. Loki responsible for log parsing and acts as a Grafana and Proemtheus data-source and Generate alerts that are sent to the Alertmanager.
Promtail load logs into Loki, there are multiple ways of doing that, we suggest to use of rsyslog, this way you can add Promtail (and Loki) as a second log collection server.
Loki Related files
Loki has a configuration file and a rule file. You need to copy and modify the configuration.
mkdir -p /etc/loki/rules
mkdir -p /etc/loki/config
cp loki/rules/scylla/* /etc/loki/rules
cp loki/conf/loki-config.template.yaml /etc/loki/config/loki-config.yaml
Edit /etc/loki/config/loki-config.yaml and replace ALERTMANAGER with the alertmanager ip:port (i.e. localhost:9093)
Promtail Related files
Promtail has a configuration file. You need to copy and modify the configuration.
mkdir -p /etc/promtail/
cp loki/promtail/promtail_config.template.yml /etc/promtail/config.yml
Edit /etc/promtail/config.yml and replace LOKI_IP with Loki’s ip:port (i.e. localhost:3100)
Install Prometheus¶
Tested with Prometheus version 2.49.1
Note
If you already have a prometheus server, beside the expected scrap jobs, make sure you take the Prometheus rules directory. The files not only contains important alerts, they are containing recording rules, without it different asspects of the dashboards will not work.
Install Prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.49.1/prometheus-2.49.1.linux-amd64.tar.gz
tar -xvf prometheus-*.linux-amd64.tar.gz
Create Data and Config directories
sudo mkdir -p /prometheus/data
sudo mkdir -p /etc/prometheus/prom_rules/
sudo mkdir -p /etc/scylla.d/prometheus/
Note
To run Promethues as non-root user, you would need to give read write and execute permissions to those directories.
Copy the following files:
scylla_servers.yml,prometheus.rules.ymlfromprometheus/directory to Prometheus installation directory.
Copy prometheus/prometheus.yml.template to prometheus.yml
For example:
cp scylla-monitoring-4.15.1/prometheus/prom_rules/*.yml /etc/prometheus/prom_rules/
cp scylla-monitoring-4.15.1/prometheus/prometheus.yml.template /etc/prometheus/prometheus.yml
Edit the
prometheus.ymlfile to point to the correct static data sources.
Note
Make sure to include the honor_labels: false parameter in the prometheus.yml file.
vi /etc/prometheus/prometheus.yml
Set the alertmanger address and port by replacing AM_ADDRESS in the file.
For example if the alertmanager will run on the same host:
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
Replace the files in to point to the right local file, typically for scylla, node_exporter and manager_agent you can use the same file (scylla_servers.yml).
For example the scrape config for Scylla:
global:
scrape_interval: 20s # By default, scrape targets every 20s second.
scrape_timeout: 15s # Timeout before trying to scape a target again
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'scylla-monitor'
scrape_configs:
- job_name: scylla
honor_labels: false
file_sd_configs:
- files:
- /etc/scylla.d/prometheus/scylla_servers.yml
relabel_configs:
- source_labels: [__address__]
regex: '([^:]+)'
target_label: __address__
replacement: '${1}:9180'
- source_labels: [__address__]
regex: '(.*):.+'
target_label: instance
replacement: '${1}'
metric_relabel_configs:
- source_labels: [__name__, scheduling_group_name]
regex: '(scylla_storage_proxy_coordinator_.*_bucket;)(atexit|gossip|mem_compaction|memtable|streaming|background_reclaim|compaction|main|memtable_to_cache)'
action: drop
- source_labels: [version]
regex: '(.+)'
target_label: CPU
replacement: 'cpu'
- source_labels: [version]
regex: '(.+)'
target_label: CQL
replacement: 'cql'
- source_labels: [version]
regex: '(.+)'
target_label: OS
replacement: 'os'
- source_labels: [version]
regex: '(.+)'
target_label: IO
replacement: 'io'
- source_labels: [version]
regex: '(.+)'
target_label: Errors
replacement: 'errors'
- regex: 'help|exported_instance'
action: labeldrop
- source_labels: [version]
regex: '([0-9]+\.[0-9]+)(\.?[0-9]*).*'
replacement: '$1$2'
target_label: svr
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_write_latency_summary;0.990*)'
target_label: __name__
replacement: 'wlatencyp99'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_write_latency_summary;0.950*)'
target_label: __name__
replacement: 'wlatencyp95'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_write_latency_summary;0.50*)'
target_label: __name__
replacement: 'wlatencya'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_read_latency_summary;0.990*)'
target_label: __name__
replacement: 'rlatencyp99'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_read_latency_summary;0.950*)'
target_label: __name__
replacement: 'rlatencyp95'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_read_latency_summary;0.50*)'
target_label: __name__
replacement: 'rlatencya'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_cas_write_latency_summary;0.950*)'
target_label: __name__
replacement: 'caswlatencyp95'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_cas_write_latency_summary;0.990*)'
target_label: __name__
replacement: 'caswlatencyp99'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_cas_write_latency_summary;0.50*)'
target_label: __name__
replacement: 'caswlatencya'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_cas_read_latency_summary;0.950*)'
target_label: __name__
replacement: 'casrlatencyp95'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_cas_read_latency_summary;0.990*)'
target_label: __name__
replacement: 'casrlatencyp99'
- source_labels: [__name__, quantile]
regex: '(scylla_storage_proxy_coordinator_cas_read_latency_summary;0.50*)'
target_label: __name__
replacement: 'casrlatencya'
- source_labels: [quantile]
regex: '(0\.[1-9]+)0*'
target_label: quantile
replacement: '${1}'
- source_labels: [__name__]
regex: '(.latency..?.?|cas.latency..?.?|scylla_.*_summary)'
target_label: by
replacement: 'instance,shard'
Note
You can change scrape_interval to a longer interval to save resources. If you do that, you must change the Grafan configuration to match it.
Create and set
scylla_servers.ymlfile point to your Scylla nodes andscylla_manager_server.ymlfile to point to your Scylla Manager.
Note
There is no need to configure node_exporter_server. Instead, in the Prometheus scrape config of the node_exporter
you can use the same file you used for Scylla and Prometheus will assume you have a node_exporter running on each Scylla server.
An example for those files can be found under the Prometheus directory: prometheus/scylla_servers.example.yml and prometheus/scylla_manager_servers.example.yml
Note
You must have both files even if you are not using Scylla Manager
Add the labels for the cluster and data-center
scylla_servers.yml:
For example:
cat /etc/scylla.d/prometheus/scylla_servers.yml
# List Scylla end points
- targets:
- 192.168.66.6
- 192.168.66.244
labels:
cluster: cluster1
dc: dc1
- targets:
- 172.17.0.3
labels:
cluster: cluster1
dc: dc2
Note
See the previous note about deprecating the node_exporter_servers.yml file.
scylla_manager_server.yml
For example:
cat /etc/scylla.d/prometheus/scylla_manager_server.yml
- targets:
- 127.0.0.1:5090
Start Prometheus server:
For example:
cd prometheus-2.49.1.linux-amd64/
./prometheus --config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path /prometheus/data
Data should start accumulate on: /prometheus/data
Verify that Prometheus is up and running, point your browser to the Prometheus IP:Port
For example:
http://192.168.135.166:9090/

Prometheus console should be visible
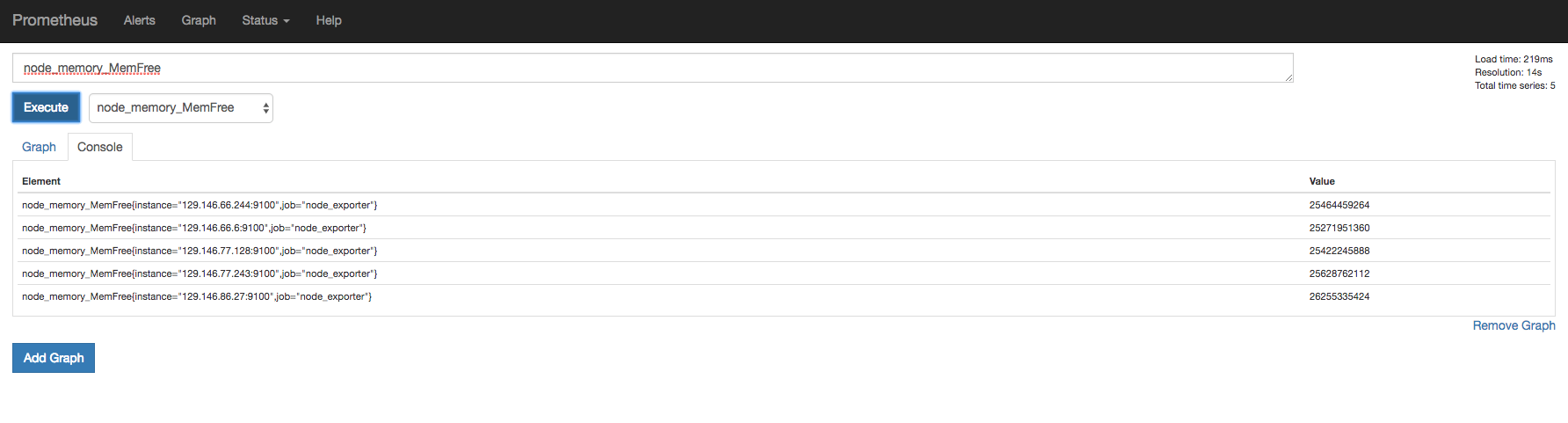
Verify that the node_exporter and scylla metrics accumulating in the server by executing a query through the console
For example:
node_memory_MemFree
And
scylla_reactor_utilization
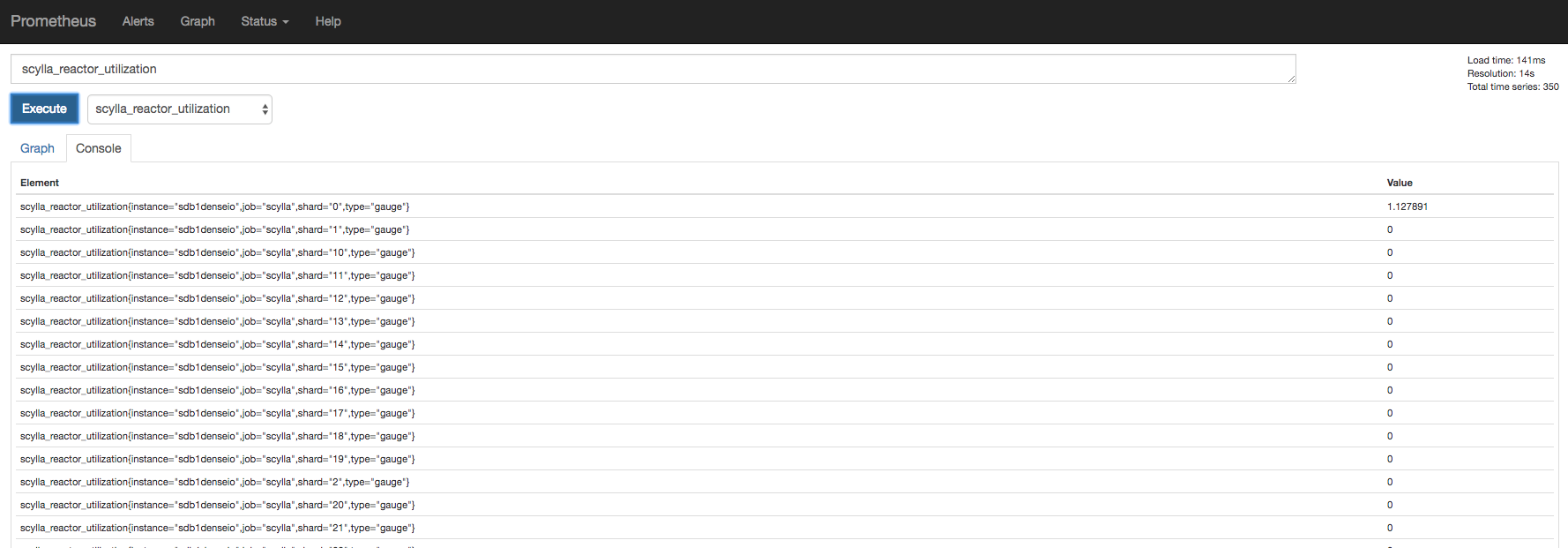
At this point Scylla is emitting the metrics and Prometheus is able to store them.
Install Grafana¶
Tested with Grafna 10.3.3
Install Grafana based on the instructions here
Depends if you installed Grafana from a repository (yum install), or if you downloaded the zip version, the directory structure will be different, we will assume that you used yum/dnf install.
Access Scylla-Grafana-monitoring directory
cd scylla-monitoring-4.15.1/
Copy the plugins to the grafana plugins directory (by default
/var/lib/grafana/)
sudo cp -r grafana/plugins /var/lib/grafana/
Provision the Dashboards
For example Scylla Open-source version 5.4 and Scylla manager version 2.4
sudo cp grafana/load.yaml /etc/grafana/provisioning/dashboards/load.5.4.yaml
sudo cp grafana/load.yaml /etc/grafana/provisioning/dashboards/load.manager_3.3.yaml
sudo mkdir -p /var/lib/grafana/dashboards
sudo cp -r grafana/build/* /var/lib/grafana/dashboards
Edit the load.* you just copied. For example
$ cat /etc/grafana/provisioning/dashboards/load.manager_3.3.yaml
apiVersion: 1
providers:
- name: 'manager_3.3'
orgId: 1
folder: ''
type: file
disableDeletion: false
allowUiUpdates: true
updateIntervalSeconds: 10 #how often Grafana will scan for changed dashboards
options:
path: /var/lib/grafana/dashboards/manager_3.3
$ cat /etc/grafana/provisioning/dashboards/load.5.4.yaml
apiVersion: 1
providers:
- name: '5.4'
orgId: 1
folder: ''
type: file
disableDeletion: false
allowUiUpdates: true
updateIntervalSeconds: 10 #how often Grafana will scan for changed dashboards
options:
path: /var/lib/grafana/dashboards/ver_5.4
Note
A note about using folders, if you provision multiple Scylla versions, use the version as a folder name. Otherwise, no need to configure a FOLDER.
Set the data source by copy
datasource.ymland edit it
sudo cp grafana/datasource.yml /etc/grafana/provisioning/datasources/
Note
Scylla uses a plugin to read from some system tables see the section below about using it.
You should set the Prometheus and the alertmanager IP and port.
For example
sudo cat /etc/grafana/provisioning/datasources/datasource.yml
apiVersion: 1
datasources:
- name: prometheus
type: prometheus
url: http://192.168.135.167:9090
access: proxy
basicAuth: false
jsonData:
timeInterval: '20s' # Must match prometheus gloabal scrape_interval
- name: alertmanager
type: camptocamp-prometheus-alertmanager-datasource
orgId: 1
typeLogoUrl: public/img/icn-datasource.svg
access: proxy
url: http://192.168.135.166:9093
password:
user:
database:
basicAuth:
isDefault:
jsonData:
implementation: 'prometheus'
Note
The timeInterval parameter must match Prometheus scrape_interval config.
Start the Grafana service
For Grafana installed with yum install
sudo service grafana-server start
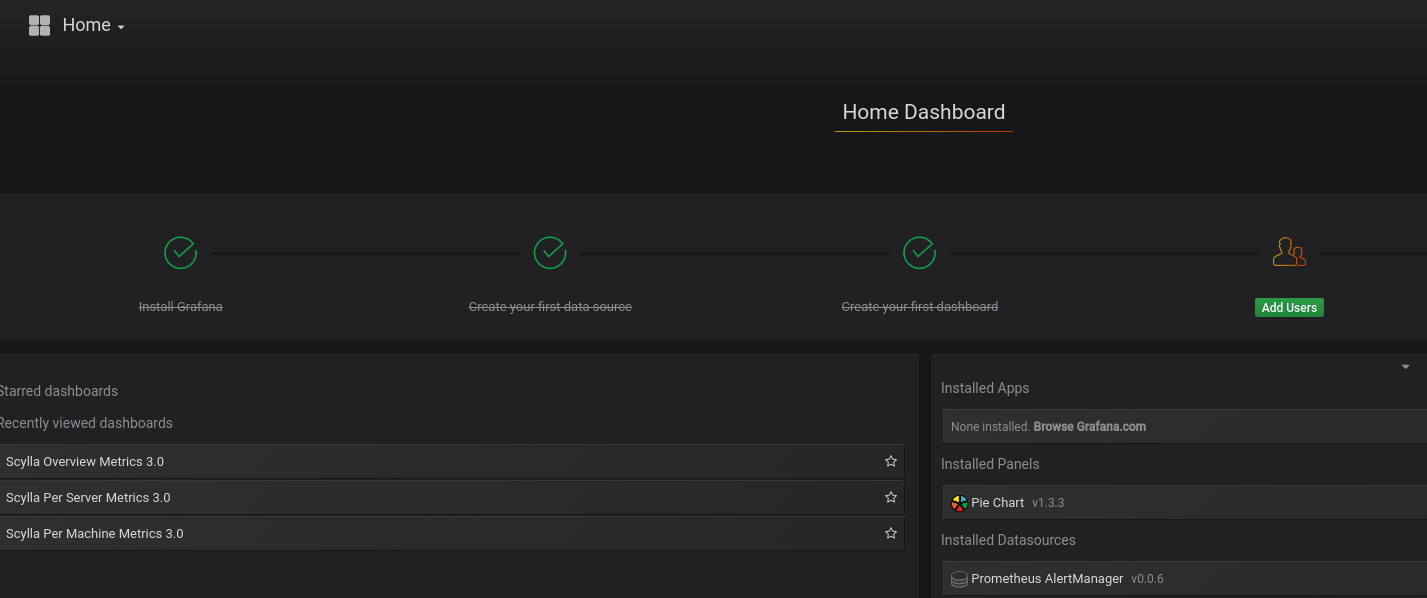
Make sure Grafana is running
Point your browser to the Grafana server port 3000, the assumption is that Grafana and Prometheus are collocated on the same server.
Using Scylla Plugin with Grafana¶
Scylla Monitoring uses a plugin to read from some of the System tables. For the plugin to work it needs to be installed, configured and there should be a CQL connectivity between the Scylla Monitoring and the Scylla servers.
Because the plugin gives access to the Scylla tables, we strongly encourage you to add a user with read-only access restricted to the system keyspace and configure the plugin to use that user.
Setting a monitoring user¶
This part is optional, but is highly recommended. The instruction at enable authorization covers all the following items in details.
If you have not done so, enable authorization first.
Add a new ROLL for the scylla monitoring:
CREATE ROLE scylla_monitoring WITH PASSWORD = 'scylla_monitoring' AND LOGIN = true;make sure to give it a proper password.Add SELECT permissions to the new user:
GRANT SELECT on KEYSPACE system TO scylla_monitoring;
Installing the Plugin¶
Grafana reads plugins from its plugin directory, copy Scylla Plugin from ‘grafana/plugins/scylla-datasource’ as described in the Grafana installation section.
Configure the Plugin¶
Add an entry to the datasource.yml file
- name: scylla-datasource
type: scylladb-scylla-datasource
orgId: 1
isDefault:
jsonData:
host: ''
# secureJsonData:
# user: 'scylla_monitoring'
# password: 'scylla_monitoring'
As mentioned previously it is safer to use a dedicated user/password for the monitoring with limited access privileges. Un-comment the relevant section if you do so, note that the username/password are only visible in the file.
Enable the Plugin¶
Grafana will not load unsigned plugins, for that you will need to enable it with Grafana. Edit Grafana grafana.ini file and add
the line allow_loading_unsigned_plugins: scylladb-scylla-datasource.
See more about it the Grafana configuration.