Was this page helpful?
Caution
You're viewing documentation for a previous version of ScyllaDB Monitoring. Switch to the latest stable version.
The CQL Optimization¶
The CQL Optimization is part of the CQL Dashboard and is a tool to help identify potential issues with queries, data model and driver.
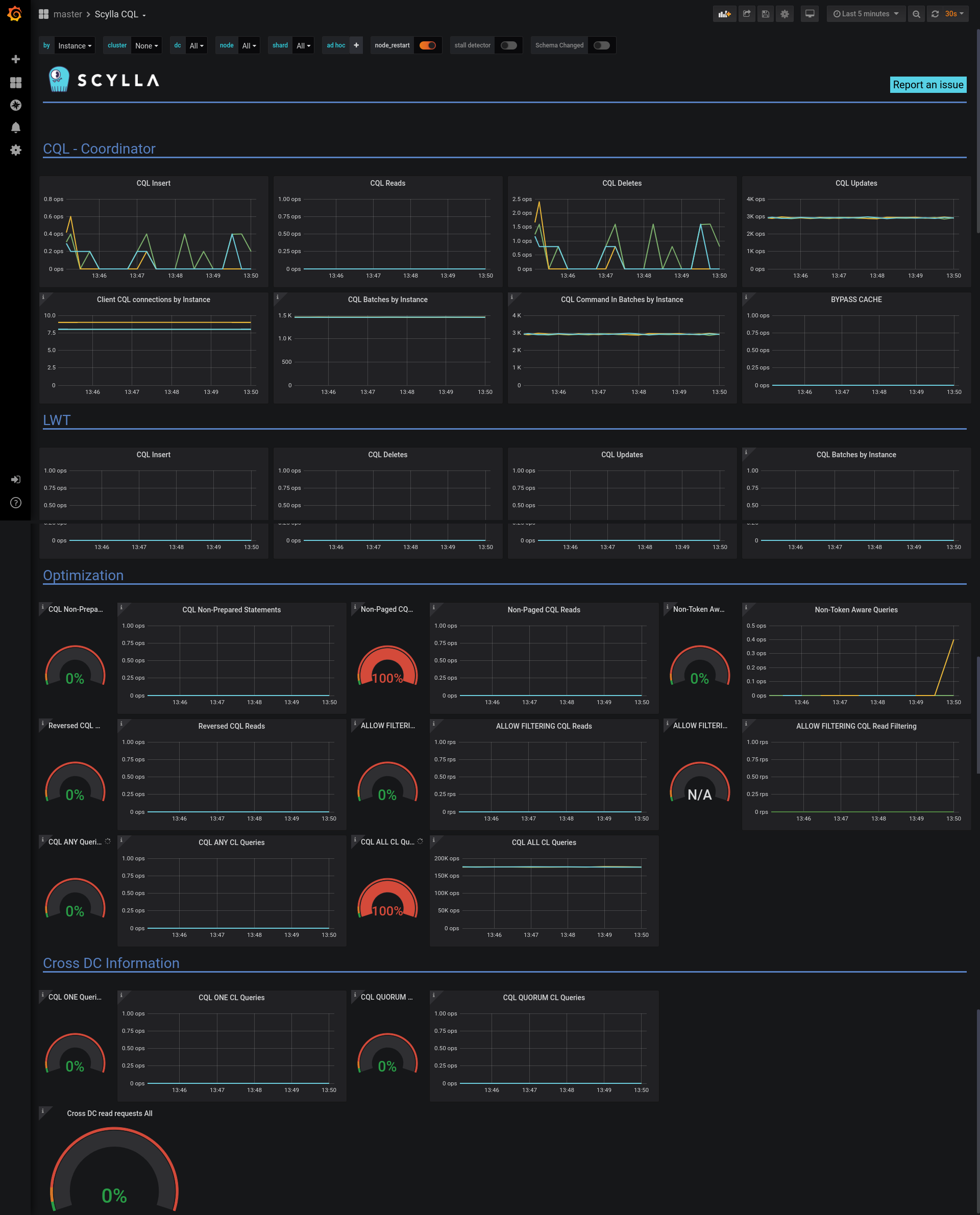
The CQL Dashboard¶
The upper part of the dashboard holds CQL related metrics.
The lower parts holds gauges and graphs. When inspecting the system, we like the gauge to be near zero and the graphs as low as possible.
Note
Besides your queries, there are queries generated by the cql driver and internal queries to the system tables which can be misleading when testing with low traffic.
The following sections describe each of the dashboard’s panel
Prepared Statements¶
Prepared statements are queries that are first defined as a template with place holders for the values and then that template is used multiple times with different values.
Using prepared statements has the following benefits:
The database only needs to parse the query once
The driver can route the query to the right node
Using place-holders and values is safer and prevents CQL-Injection
The CQL Non-Prepared Queries Gauge shows the percentage of queries that are not prepared.
The CQL Non-Prepared Queries Graph shows the rate of the queries. Make sure both are low.
Token Aware¶
Scylla is a distributed database, where each node contains only part of the data, specifically a range of the token ring. Ideally, a query would reach the node that holds the data (one of the replicas), failing to do so would mean the coordinator needs to send the query internally to a replica. This results in higher latency and increased resource usage.
Typically, your driver would know how to route the queries to a replication node, but using non-prepared statements, non-token-aware driver or load-balance can cause the query to reach a node that is not a replica.
The Non-Token Aware Gauge shows the percentage of queries that reached a node that does not hold that data (a node that is not a replica-node).
The Non-Token Aware Queries Graph shows the rate of the queries that did not reach a replica-node, make sure both are low.
Paged Queries¶
By default, read queries are paged, this means that Scylla will break the results into multiple chunks limiting the reply size. Non-Paged queries require all results be returned in one result increasing the overall load of the system and clients and should be avoided.
The Non-Paged CQL Reads Gauge shows the percentage of non-paged read queries that did not use paging.
The Non-Paged CQL Reads Graph shows the rate of the non-paged queries, make sure both are low.
Reversed CQL Reads¶
ScyllaDB supports compound primary keys with a clustering column. This kind of primary keys allows an efficient way to return sorted results that are sorted by the clustering column.
We strongly recommend using use the correct ordering.
Querying with an order different than the order the CLUSTERING ORDER BY was defined is supported, but not advisable.
For example, look at the following table:
CREATE TABLE ks1.table_demo (
category text,
type int,
PRIMARY KEY (category, type))
WITH CLUSTERING ORDER BY (type DESC);
The following query uses reverse order:
select * from ks1.table_demo where category='cat1' order by type ASC;
The Reversed CQL Reads Gauge shows the percentage of read queries that use ORDER BY that is different than the CLUSTERING ORDER BY.
The Reversed CQL Reads Graph shows the rate of the read queries that use ORDER BY that is different than the CLUSTERING ORDER BY, make sure both are low.
ALLOW FILTERING¶
Scylla supports server side data filtering that is not based on the primary key. This means Scylla would read data and then filter and return part of it to the user. Data that is read and then filtered is an overhead to the system.
These kinds of queries can create a big load on the system, and should be used with care.
The CQL optimization dashboard, checks for two things related to queries that use ALLOW FILTERING: how many such queries exist; and how much of the data that was read was
dropped before returning to the client.
The ALLOW FILTERING CQL Reads Gauge shows the percentage of read queries that use ALLOW FILTERING.
The ALLOW FILTERING CQL Reads Graph shows the rate of the read queries that use ALLOW FILTERING, make sure both are low.
The ALLOW FILTERING Filtered Rows Gauge shows the percentage of rows that were read and then filtered, this is an indication of the additional overhead to the system.
The ALLOW FILTERING Filtered Rows Graph shows multiple graphs: the rows that were read, the rows that matched and the rows that were dropped. Rows that were dropped are an additional overhead to the system.
Consistency Level¶
Typically data in Scylla is duplicated into multiple replicas for availability reasons. A coordinator node would get the request and will send it to the nodes holding the replicas.
The query Consistency Level determines how many replies from the replicas are required before the coordinator replies to the client. The most common case is to use QUORUM, which means that when the coordinator gets a majority of the replies from the replicas, it will return success to the client.
Two consistency levels hold a potential problem and should be used with care ANY and ALL.
The CQL ANY Queries Gauge shows the percentage of queries that use Consistency Level ANY. Using consistency level ANY in a query may hurt persistency, if the node receiving the request fails, the data may be lost.
The CQL ANY CL Queries Graph shows the rate of the queries that use Consistency Level ANY, make sure both are low.
The CQL ALL CL Queries Gauge shows the percentage of queries that use Consistency Level ALL. Using consistency level ALL in a query may hurt availability, if a node is unavailable the operations will fail.
The CQL ALL CL Queries Graph shows the rate of the queries that use Consistency Level ALL, make sure both are low.
Cross DC¶
Cross DC traffic is usually more expensive in terms of latencies and cost. This metric reports on such traffic in situations were it could be avoided.
Cross DC Consistency Level¶
Using consistency level QUORUM or consistency level ONE in a query when there is more than one DC may hurt performance, as queries may end in the non-local DC. Use LOCAL_QUORUM and LOCAL_ONE instead.
Cross DC read requests¶
Note
The CQL Optimization Dashboard relies on the definition of nodes per Data Center in the Scylla Monitoring Stack (prometheus/scylla_servers.yml) to match the Data Center names used in Scylla Cluster. If this is not the case, you will see the wrong result.
In a typical situation, a client performs a read from the nearest data-center and that query is performed local to the data-center. A read request that ends up causing traffic between data-centers adds additional overhead to the system.
The Cross DC read requests Gauge shows the percentage of read queries that caused a request to an external data-center, make sure it is low or zero.